

機械学習に必須のライブラリ、scikit-learnとは?〜癌データの識別例で学ぶscikit-learn入門チュートリアル〜
こんにちは!PA Labメディアです。
Pythonで機械学習は難しそうだなと思っている方も多いのではないでしょうか。実は機械学習の使用自体はライブラリを使用することで簡単に実装する事が可能です。特に最も有名なscikit-learnという機械学習ライブラリの紹介をしていきます。
今回の記事では以下のような方を対象にしております。
- 「Pythonの機械学習ライブラリであるscikit-learnについて知りたい」
- 「実際にscikit-learnを使えるようにしたい」
- 「scikit-learnによる機械学習の実装を試してみたい」
本記事は上記のような方を対象にした記事となっています。
scikit-learnを使うことで、高度な機械学習を手軽に行うことができます。しかし、分析結果や予測をビジネスに活用するには、データサイエンスや機械学習の知識が必要になってきます。
また学習サイトで実務で使われるようなケーススタディを学ぶ必要も出てくるかと思います。例えば、「コンビニの購買履歴データを分析して、Aを買う人はBも買う可能性が高い」などの価値のあるルールを見つけ、陳列に反映した、などのケーススタディを学ぶことで、機械学習をビジネスに活用できるようになっていくかと思います。
目次
scikit-learnとは
scikit-learnとは
scikit-learn(サイキット・ラーン)はPythonでよく使用される機械学習ライブラリで、BSDライセンスのオープンソースライブラリです。元々はscikits.learnというライブラリでsklearnとしても知られています。色々なアルゴリズムが網羅されており、回帰モデルや分類モデルに始まり、クラスタリングやSVM、ランダムフォレスト、最近ではGBDT、k-meansなども入っています。NumPyやSciPyと組み合わせて使用される設計になっているため、高速な処理を行っています。
scikit-learnは現在最も有名な機械学習のライブラリの一つですが、元々scikits.learnはGoogle Summer of Codeと呼ばれるプロジェクトで学生のDavid Cournapeauが立ち上げていたプロジェクトです。オリジナルのコードは別の開発者によって更に書き換えられて、フランスの研究機関French Institute for Research in Computer Science and Automationによって現在は進められているプロジェクトになります。
機械学習チートシートについて
以下のシートは、scikit-learnの機械学習チートシートと呼ばれるシートです。どのような分析を行い、どのアルゴリズムを選択すべきかを分類したものです。教師あり、教師なし、また、サンプル数の大きさなどで分類しています。教師あり学習とは、実際の正解ラベルを元に学習を行う機械学習の手法のことです。
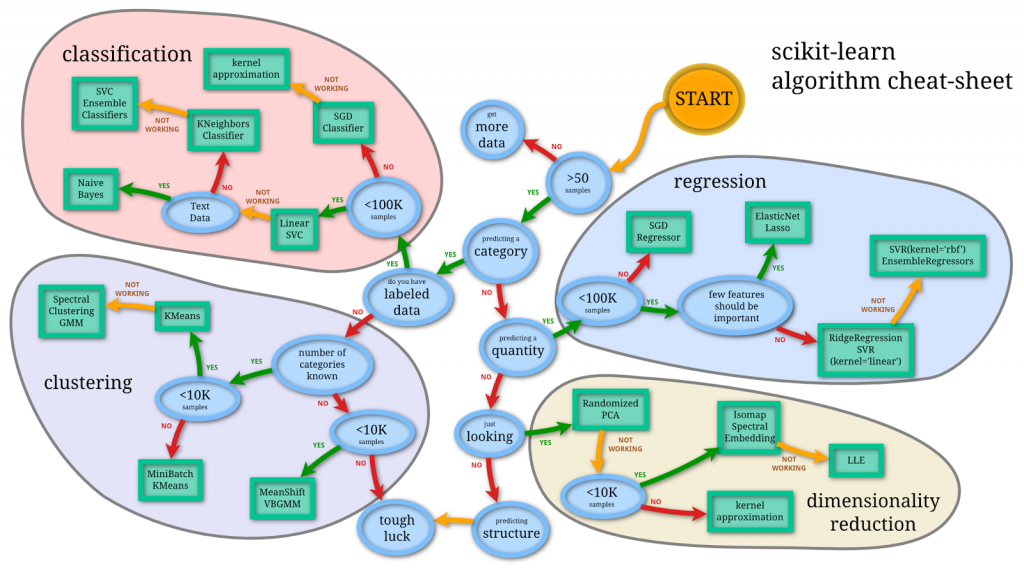
少し古いものなので今ではあまり使用される事はそこまでありませんが、大まかな流れとしてはこのチートシートに沿って進める形になっています。
scikit-learnの6つの機能紹介
scikit-learnには、大きく分けて6つの機能があります。以下に簡単に内容を記します。
今回後半で扱うロジスティック回帰は少しややこしいのですが、確率の回帰モデルであり分類を行うアルゴリズムとなっています。
scikit-learnの機能1: 識別(分類)
データがどのカテゴリに属するかを識別します。
例えばGメールで使用されているようなスパムメール分類、画像分類などが分かりやすい例です。
アルゴリズムとしてはSVM、最近某探索、ランダムフォレストなどが挙げられます。
scikit-learnの機能2: 回帰
与えられたデータから連続値を予測する回帰です。
例えば株価予測などが分かりやすい例です。
SVR、最近某探索、ランダムフォレストなどが挙げられます。
scikit-learnの機能3:クラスタリング
クラスタリングは、類似しているデータをグループ化します。
カスタマーのセグメンテーションが例として挙げられます。
手法としてはk-means、スペクトラルクラスタリングが入っています。
scikit-learnの機能4:次元削減
理解を深めるためにデータの次元数を削減します。
例えばデータの可視化、効率化のために行います。
挙げられている手法としてはk-means、非負行列因子分解があります。
scikit-learnの機能5: モデル選択
比較、評価、パラメータ選択やモデル選択を行う機能です。
よく使用される例としてはパラメータチューニングを行い、より精度の高いモデルを選択するアプローチがあります。
グリッドサーチやクロスバリデーションなどがあります。
scikit-learnの機能6: 前処理
特徴量選択、データの正規化の機能などの前処理の機能も含まれています。
例えばテキストデータのようなデータの変換だったり、画像データの標準化なども簡単に行う事が出来ます。
scikit-learnの始め方
Anacondaのインストール
Anacondaをインストールすることで、scikit-learnを簡単に扱うことができます。Anacondaは、最も使われているPythonディストリビューションで、データサイエンスに必要なパッケージを一挙にインストールすることができます。
Numpy、Pandas、matplotlib、Jupyter Notebookなどのデータ解析によく使うパッケージも含まれているので、インストールしておきましょう。
Anacondaにscikit-learnがあるかを確認する
Anacondaがインストールできたら、scikit-learnが入っているか確認しておきましょう。メニューカラムのEnvironmentsをクリックし、パッケージの検索窓(Search Packages)からscikitと検索します。検索結果にscikit-learnが表示されれば、使える状態になっています。

scikit-learnによる機械学習の実装
癌データの識別について(ロジスティック回帰)
最後に、次のような機械学習の実装例を試してみましょう。今回のデータセットの例では「569個の癌のデータセットを使用して、ひとつひとつのデータが悪性(Malignant)か良性(Benign)かを識別、予測する」というものです。悪性が0、良性が1とラベル付けされており、それぞれ特徴量が30個あります。悪性か良性か、2つに識別するので、2クラス問題などと呼ばれます。
まずデータセットを、学習データとテストデータに分割します。次に識別器を作成して学習データを用いて学習を行います。ここでは、ロジスティック回帰の識別器を作成します。学習結果をもとに、テストデータに対して予測を行います。そして、その予測が実際のテストデータとどのくらい合っていたかを確認します。
特徴量は癌の半径や表面の質感(テクスチャ)などの値を使って統計的な学習を行うので、未知のデータに対して悪性だ、というように予測を行うことができます。
モジュールとデータのインポート
まず、機械学習に必要なモジュールのインポートをします。Pandas、Numpy、matplotlib、seabornは、データ解析の際に一緒にインポートされることが多いのでインポートしておきます。matplotlibとseabornは、Pythonのデータ可視化ライブラリです。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns以下のコードで、scikit-learnから癌のデータを読み込みます。
PandasのDataFrameでデータイメージを見てみましょう。`df = pd.read_csv(“filepath”)`でcsvファイルを読み込み、dfを実行します。(csvは、後ほど出てくるデータディスクリプションのURLから取得できます)

ソースコードの確認
以下がソースコードになります。
# 基本モジュール
import pandas as pd
import numpy as np
# 可視化のためのモジュール
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer # 癌のデータをインポート
df = pd.read_csv("/Users/username/Desktop/data.csv")
data = load_breast_cancer() # データをセットする
X = data.data # セットしたdataのdata属性(特徴量)を、Xとする
y = data.target # セットしたdataのtarget属性(ラベル)を、yとする
X.shape # データ個数, 特徴量
y.shape # データ個数(ラベルの数)
data.target_names # ラベルの意味
print(data.DESCR) # データディスクリプション
from sklearn import linear_model # 線形モデルを準備
clf = linear_model.LogisticRegression() # 識別器を作成
clf
# データセットを分割する関数のインポート
from sklearn.model_selection import train_test_split
# 学習データとテストデータへ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
import warnings # 'lbfgs'の警告を非表示に
warnings.filterwarnings('ignore')
clf.fit(X_train, y_train); # 識別器の学習
clf.score(X_train, y_train) # 学習データの予測の正答率
clf.score(X_test, y_test) # テストデータの予測の正答率
clf.predict(X_test) # テストデータの予測結果
# テストデータの予測結果と、実際のテストデータの正誤
a = clf.predict(X_test)
b = y_test
pd.set_option('display.max_rows', 200)
pd.DataFrame(a == b)
df = pd.DataFrame({'A': a == b})
print(df['A'].value_counts())実装の手順
実装の手順を見ていきましょう。以下のコードですでに用意されているデータをロードします。
data = load_breast_cancer()セットしたdataのload_breast_cancerには、dataという属性に特徴量が、targetという属性にラベルがそれぞれ入っています。これを、機械学習用にX、yという変数に格納します。(PythonではXを大文字、yを小文字にするのが慣例です)
X = data.data
y = data.targetX、yの中身をそれぞれ確認してみます。Xにはデータ個数分の特徴量が入っています。

yにはデータ個数分のラベルが入っています。

ラベルの内容を確認してみます。0が悪性、1が良性となっています。

デモデータのため、データの詳細も確認することが出来ます。

ロジスティックモデルのクラスを呼び出して、clfモデルを構築します。
clfは一般的にclassificationで分類モデルを表しています。
from sklearn import linear_model
clf = linear_model.LogisticRegression()
clfの中身を確認してみましょう。
ここではデフォルトのパラメータが設定されています。

データセットを、学習データとテストデータが7 : 3になるように分けます。まず、train_test_splitという関数をインポートします。ここで、引数にtest_size=0.3を入れることで、データセットの30%をテストデータとして指定することができます。残りの70%は自動的に学習データに割り当てられます。今回はデモのため、random_state=0として、常に同じデータが分割されるようにしておきます。(random_stateは、乱数シードを固定する引数として使われます)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
学習データに対して、識別器で学習を行います。clf.fit()というメソッドで、実際の学習を実行できます。
clf.fit(X_train, y_train);
学習結果をもとに、学習データの精度検証を行います。clf.score()メソッドで、予測の決定係数を返すことができます。ここでは数式は割愛していますが、決定係数は最大値が1で大きい値になっていればいるほどモデルが与えられているデータに当てはまっている事を表しています。
clf.score(X_train, y_train)
学習結果をもとにテストデータの精度検証を行います。未知のテストデータに対する予測で0.96の決定係数が出ています。最大でも決定係数は1なので、まずまずの高い性能があると言えそうです。
clf.score(X_test, y_test)
clf.predict()メソッドで、実際にどのような予測結果となったのかを確認できます。
clf.predict(X_test)
最後にテストデータの予測結果と、実際のテストデータの正誤を確認します。
実際の評価はこのAccuracy(精度)と呼ばれる評価を用いて行います。
value_countsで、True、Falseをカウントできます。171個中、6個間違っていることがわかりました。
df = pd.DataFrame({'A': a == b})
print(df['A'].value_counts())
今回の例では精度としてはなかなか高いようなので、そもそも良い特徴量があり分類問題としてはそこまで難しくなかったようですね。
まとめ
今回は、Pythonの機械学習ライブラリ、scikit-learnについて紹介しました。scikit-learnのインストールから、データセットを使った実装例までを解説しました。scikit-learnを使うことで、機械学習を試すことができました。今回使ったロジスティック回帰以外にも、識別(分類)のアルゴリズムだけで、SGD(確率勾配法)、カーネル近似、Linear SVC、k近傍法、ナイーブベイズなどがあります。
scikit-learnによる機械学習は、手軽に始めることができるかと思います。一方で、それを使いこなしていくには統計的な理解が必要であり、そのためには実務のケーススタディを学ぶのが一番の近道かと思います。
PA Labでは「AIを用いた自動化×サービス開発」の専門家として活動をしています。高度なデータ分析からシステム開発まで一貫したサービス提供を行っており、特に機械学習やディープラーニングを中心としたビジネス促進を得意としております。
無料で分析設計/データ活用に関するご相談も実施中なので、ご相談があればお問い合わせまで。






この記事へのコメントはありません。