

Intel製のアノテーションツール「CVAT」とアノテーションの活用事例
こんにちは!PA Labメディアです。
今回はCVATと呼ばれる画像・動画向けのアノテーションツールを紹介していきたいと思います。
目次
アノテーションツールとは
アノテーションとは「注釈」という意味の英単語ですが、機械学習の分野では正解データを人手で付与する事を意味します。AIモデルを作成するような機械学習のプロジェクトでは、データ収集と呼ばれる工程があります。
大体の画像や動画を扱う機械学習のプロジェクトでは、このアノテーションと呼ばれる作業を行なう事で効率良く学習データを収集していく必要があります。
例えば、物体検出と呼ばれるタスクのアノテーションであれば、検出したい対象(この例ではコーヒー)に対して、人が正解の領域を付与する行為になります。

上記のような正解データを大量にアノテーションすることで学習データを収集して、未知の画像に対しても予測ができるようなモデルを作成していく、といったプロセスになります。上記の物体検出の例であれば、具体的には「別の喫茶店で撮ったコーヒーの物体検出が出来る」という事を目指していきます。
このようなアノテーションの作業を効率よく行なう事ができるのがCVATのようなアノテーションツールになります。
CVATの特徴
CVATの特徴(1) Intelが開発したコンピュータービジョン向けアノテーションツール
CVAT(Computer VIsion Annotation Tool)はIntelが作成しているOSS(オープンソースソフトウェア)の画像・動画向けのアノテーションツールです。特にコンピュータービジョンでよく用いられるようなタスク(具体的には領域検出、画像分類、セマンティックセグメンテーションのようなタスク)で使用することが出来ます。
MITライセンスでコード自体もGithubで配布されています。さらにDjangoで開発されているので、ある程度柔軟にCVATのライブラリそのものをカスタムしていくことも可能です。
CVATの特徴(2) 多様なインターフェースのサポート
CVAT自体はDjangoで作成されたライブラリになりますが、インターフェースがいくつかあり基本はブラウザ上で使用することが出来ます。そのためサーバーで設定してしまえば、複雑な環境設定が必要なく他のユーザーは簡単に使用することが出来ます。
またCLI操作やAWSでのデプロイのサポートなどアノテーションツールにしてはかなり豊富にインタフェースがサポートされています。
CVATの特徴(3) 豊富なアノテーションフォーマット
またCVATはIntelが開発していることもあり豊富なアノテーションフォーマットを採用しています。
大体のフォーマットで、インポート・エクスポート両方可能なので、統一したフォーマットにする事も可能です。
例えば、TFRecordなども採用しているため、そのままTensorFlow(Googleが作成した深層学習のライブラリ)と組み合わせて使用する事も可能です。
アノテーションが必要な事例
コンピュータービジョンによる建物劣化の自動検出
経験豊富な作業員が目視で判断していた作業をAIで代替して、熟練の職人芸がなくてもAI技術により人件費の大幅なコスト削減や、職人への教育リソース問題などを解決することが出来ます。
このような例では、建物の劣化を種類別にアノテーションする事が考えられますが、CVATを社内で導入する事でアノテーション自体も早く行なう事ができますし、学習データを沢山収集する事でAIによる予測モデルを作成することが出来ます。
以下のようにひびが入った箇所に対して自動検出のモデルを作成する事で、大量の建物画像に対して予測を行い、大幅な作業効率化を行なう事が出来ます。

自動運転技術で用いられる車や道路の認識
こちらは自動運転の研究でよく用いられている技術になります。
自動運転の研究では他の車の位置や道路の情報、歩行者などあらゆる外部的な情報を認識する必要があります。
自動運転技術では昔からLiDARと呼ばれるレーダー光を使用したセンサーが使用されており、物体の位置や形状なども含めて正確に検知出来る事が出来ます。ただし、LiDARは一般的には高価であり、また複数の情報を元に物体検知を行なう方が正確なので、近年はカメラ画像を用いたセマンティックセグメンテーションによる車や道路などの認識を行なう技術の研究が盛んに行われています。
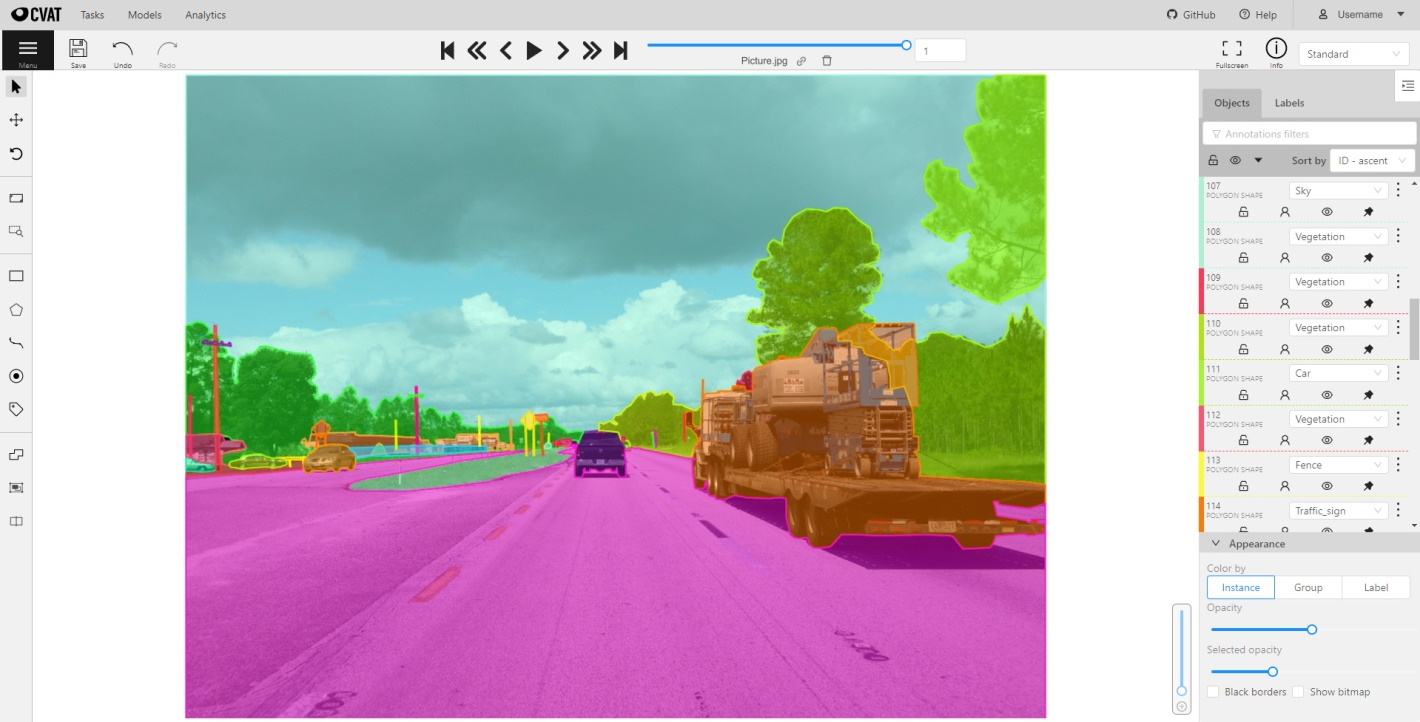
すでに作成されているデータセットも存在しますが、例えば雨天や豪雪のような、日本の道路状況への対応などを考慮すると、基本的には改めて人手で付与していく必要があります。今回のような自動運転で用いる画像のアノテーションでは以下の画像のようにラベルごとに色を分けて塗るようなイメージになります。
例えば空、道路、車、歩行者、などそれぞれ別のラベルになっており、それぞれの対象ごとにCVATを用いてラベルを付与していく形になっています。この例では道路は紫色、空は青色、植物は緑色でアノテーションを行っています。
CVATでアノテーションを行う手順
CVATのインストール
簡単にDockerのみで動作するようになっているため、Mac上でDockerがインストールされているとこれだけでCVAT環境を導入する事が出来ます。
$ git clone https://github.com/opencv/cvat
$ cd cvat
$ docker-compose up -d新規タスク作成
Dockerを立ち上げるとローカル環境でサーバーが立ち上がるため、こちらからタスクを設定していきます。
アノテーションの新規タスクを作成していき、こちらから「分類問題」、「物体検出(オブジェクトディテクション)」、「セマンティックセグメンテーション」などのタスクやラベルの作成を行っていきます。

今まで社内でのアノテーションデータの作成が大変だったり、人にアノテーション作業を行なう際もこのようなソフトウェアがないとかなり不便でしたが、CVATのおかげで非常に簡単に作成していくことが出来るようになりました。
まとめ
今回はCVATの簡単な紹介とアノテーション画像の実際の応用例を紹介しました。
CVATのおかげで不便だったアノテーション作業がかなり楽に行う事が出来るようになりましたし、多様なフォーマットに対応していてOSSになっているのも非常にありがたいですね。
簡易的なアノテーションの例を解説しましたが、実際に画像を用いた機械学習プロジェクトでは評価設計、ラベルの妥当性、機械学習モデルの構築など他にも沢山行なうべき作業があります。
PA Labでは「AIを用いた自動化×サービス開発」の専門家として活動をしています。高度なデータ分析からシステム開発まで一貫したサービス提供を行っており、特に機械学習やディープラーニングを中心としたビジネス促進を得意としております。
無料で分析設計/データ活用に関するご相談も実施中なので、ご相談があればお問い合わせまで。






この記事へのコメントはありません。